1.Mysq主从简介
随着系统应用访问量逐渐增大,单台数据库读写访问压力也随之增大,当读写访问达到一定瓶颈时,将数据库的读写效率骤然下降,甚至不可用。
为解决此类问题,通常会采用MySQL集群,当主库宕机后,集群会自动将一个从库升级为主库,继续对外提供服务;那么主库和从库之间的数据是如何同步的呢?本文将分理论和实践两个角度分别进行介绍。
原理:
主从复制的原理?
1.数据库有个bin-log二进制文件,记录了所有sql语句。
2.我们的目标就是把主数据库的bin-log文件的sql语句复制过来。
3.让其在从数据的relay-log重做日志文件中再执行一次这些sql语句即可。
4.下面的主从配置就是围绕这个原理配置
5.具体需要三个线程来操作:
1.binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。在从库里,当复制开始的时候,从库就会创建两个线程进行处理:
2.从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
3.从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。
对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
2.概念
2.1 MySQL复制是什么?(WHAT?)
为了减轻主库的压力,应该在系统应用层面做读写分离,写操作走主库,读操作走从库。下图为MySQL官网给出的主从复制的原理图,从图中可以简单的了解读写分离及主从同步的过程,分散了数据库的访问压力,提升整个系统的性能和可用性,降低了大访问量引发数据库宕机的故障率。
复制的结果是集群(Cluster)中的所有数据库服务器得到的数据理论上都是一样的,都是同一份数据,只是有多个copy。MySQL默认内建的复制策略是异步的,基于不同的配置,Slave不一定要一直和Master保持连接不断的复制或等待复制,我们可以指定复制所有的数据库,一部分数据库,甚至是某个数据库的某部分的表。
2.1.1 复制策略
MySQL复制支持多种不同的复制策略,包括同步、半同步、异步和延迟策略等。
- 同步策略:Master要等待所有Slave应答之后才会提交(MySql对DB操作的提交通常是先对操作事件进行二进制日志文件写入然后再进行提交)。
- 半同步策略:Master等待至少一个Slave应答就可以提交。
- 异步策略:Master不需要等待Slave应答就可以提交。
- 延迟策略:Slave要至少落后Master指定的时间。
2.1.2 复制模式
根据binlog日志格式的不同,MySQL复制同时支持多种不同的复制模式:
- 基于语句的复制,即Statement Based Replication(SBR):记录每一条更改数据的sql
- 优点:binlog文件较小,节约I/O,性能较高。
- 缺点:不是所有的数据更改都会写入binlog文件中,尤其是使用MySQL中的一些特殊函数(如LOAD_FILE()、UUID()等)和一些不确定的语句操作,从而导致主从数据无法复制的问题。
- 基于行的复制,即Row Based Replication(RBR):不记录sql,只记录每行数据的更改细节
- 优点:详细的记录了每一行数据的更改细节,这也意味着不会由于使用一些特殊函数或其他情况导致不能复制的问题。
- 缺点:由于row格式记录了每一行数据的更改细节,会产生大量的binlog日志内容,性能不佳,并且会增大主从同步延迟出现的几率。
- 混合复制(Mixed)
一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。
2.2 MySQL的复制有什么好处?(WHY)
- 性能方面:MySQL复制是一种Scale-out方案,也即“水平扩展”,将原来的单点负载扩散到多台Slave机器中去,从而提高总体的服务性能。在这种方式下,所有的写操作,当然包括UPDATE操作,都要发生在Master服务器上。读操作发生在一台或者多台Slave机器上。这种模型可以在一定程度上提高总体的服务性能,Master服务器专注于写和更新操作,Slave服务器专注于读操作,我们同时可以通过增加Slave服务器的数量来提高读服务的性能。——实现“读”与“写”分离
- 故障恢复:同时存在多台Slave提供读操作服务,如果有一台Slave挂掉之后我们还可以从其他Slave读取,如果配置了主从切换的话,当Master挂掉之后我们还可以选择一台Slave作为Master继续提供写服务,这大大增加了应用的可靠性。
- 数据分析:实时数据可以存储在Master,而数据分析可以从Slave读取,这样不会影响Master的性能。
2.3 MySQL如实实现主从复制?(HOW)
mysql主从复制需要三个线程,master(binlog dump thread)、slave(I/O thread 、SQL thread)。
- master
- binlog dump线程:当主库中有数据更新时,那么主库就会根据按照设置的binlog格式,将此次更新的事件类型写入到主库的binlog文件中,此时主库会创建log dump线程通知slave有数据更新,当I/O线程请求日志内容时,会将此时的binlog名称和当前更新的位置同时传给slave的I/O线程。
- slave
- I/O线程:该线程会连接到master,向log dump线程请求一份指定binlog文件位置的副本,并将请求回来的binlog存到本地的relay log中,relay log和binlog日志一样也是记录了数据更新的事件,它也是按照递增后缀名的方式,产生多个relay log( host_name-relay-bin.000001)文件,slave会使用一个index文件( host_name-relay-bin.index)来追踪当前正在使用的relay log文件。
- SQL线程:该线程检测到relay log有更新后,会读取并在本地做redo操作,将发生在主库的事件在本地重新执行一遍,来保证主从数据同步。此外,如果一个relay log文件中的全部事件都执行完毕,那么SQL线程会自动将该relay log 文件删除掉。
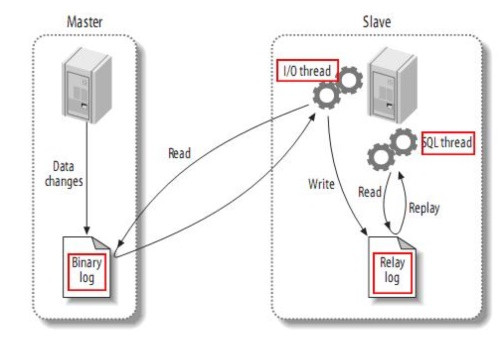
- 主库将更新以事件的形式记录到二进制日志(Binary log)文件中;
- 从库开启IO线程,与主库建立普通连接;主库开启二进制转储线程,将二进制日志中的内容发送到从库;从库IO线程收到主库的内容后,写入到从库的中继日志(Relay log)文件中;
需要注意的是,二进制转储线程不是轮询的,如果该线程追改上主库的更新线程,则进入sleep状态,由主库进行唤醒;二进制日志与中继日志相同;
- 从库开启SQL线程,读取并且重放中继日志中的事件,实现与主库的一致;
2.4 主从同步的延迟
mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高,slave的I/O线程到主库取日志,效率也比较高,但是,slave的SQL线程将主库的DDL和DML操作在slave实施。DML和DDL的IO操作是随即的,不是顺序的,成本高很多,还可能存在slave上的其他查询产生lock争用的情况,由于SQL也是单线程的,所以一个DDL卡住了,需要执行很长一段事件,后续的DDL线程会等待这个DDL执行完毕之后才执行,这就导致了延时。当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围,延时就产生了,除此之外,还有可能与slave的大型query语句产生了锁等待导致。
由于主从同步延迟是客观存在的,我们只能从我们自己的架构上进行设计, 尽量让主库的DDL快速执行。下面列出几种常见的解决方案:
- 业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力。
- 服务的基础架构在业务和mysql之间加入memcache或者Redis的cache层。降低mysql的读压力;
- 使用比主库更好的硬件设备作为slave;
- sync_binlog在slave端设置为0。该选项控制mysql怎么刷新二进制日志到磁盘,默认是0,意味着mysql并不刷新,由操作系统自己决定什么时候刷新缓存到持久化设置,如果这个值比0大,它指定了两次刷新到磁盘的动作之间间隔多少次二进制日志写操作;
- 禁用slave库的binlog。
通常情况,从服务器从主服务器接收到的更新不记入它的二进制日志。该选项告诉从服务器将其SQL线程执行的更新记入到从服务器自己的二进制日志。为了使该选项生效,还必须用--logs-bin选项启动从服务器以启用二进制日志。如果想要应用链式复制服务器,应使用
--logs-slave-updates。
例如,可能你想要这样设置:
graph LR A-->B B-->C
也就是说,A为从服务器B的主服务器,B为从服务器C的主服务器。为了能工作,B必须既为主服务器又为从服务器。你必须用--logs-bin启动A和B以启用二进制日志,并且用--logs-slave-updates选项启动B。
2.5 其他问题
问题一:通过复制模型虽然读能力可以通过扩展slave机器来达到提高,而写能力却不能,如果写达到瓶颈我们应该怎么做呢?
答:我们首先会得出结论,这种复制模型对于写少读多型应用是非常有优势的,其次,当遇到这种问题的时候我们可以对数据库进行分库操作,所谓分库,就是将业务相关性比较大的表放在同一个数据库中,例如之前数据库有A,B,C,D四张表,A表和B表关系比较大,而C表和D表关系比较大,这样我们把C表和D表分离出去成为一个单独的数据库,通过这种方式,我们可以将原有的单点写变成双点写或多点些,从而降低原有主库的写负载。
问题二:因为复制是有延迟的,肯定会发生主库写了,但是从库还没有读到的情况,遇到这种问题怎么办?
答:MySQL支持不同的复制策略,基于不同的复制策略达到的效果也是不一样的,如果是异步复制,MySQL不能保证从库立马能够读到主库实时写入的数据,这个时候我们要权衡选择不同复制策略的利弊来进行取舍。所谓利弊,就是我们是否对从库的读有那么高的实时性要求,如果真的有,我们可以考虑使用同步复制策略,但是这种策略相比于异步复制策略会大大降低主库的响应时间和性能。我们是否可以在应用的设计层面去避开这个问题?
问题三:复制的不同模式有什么优缺点?我们如何选择?
答:基于语句的复制实际上是把主库上执行的SQL在从库上重新执行一遍,这么做的好处是实现起来简单,当前也有缺点,比如我们SQL里面使用了NOW(),当同一条SQL在从库中执行的时候显然和在主库中执行的结果是不一样的,诸如此类问题可以类推。其次问题就是这种复制必须是串行的,为了保证串行执行,就需要更多的锁。
基于行的复制的时候二进制日志中记录的实际上是数据本身,这样从库可以得到正确的数据,这种方式缺点很明显,数据必须要存储在二进制日志文件中,这无疑增加的二进制日志文件的大小,同时增加的IO线程的负载和网络带宽消耗。而相比于基于语句的复制还有一个优点就是基于行的复制无需重放查询,省去了很多性能消耗。
无论哪种复制模式都不是完美的,日志如何选择,这个问题可以在理解他们的优缺点之后进行权衡。
三、主从同步配置实战
3.1 准备工作
演示之前,需要两台安装有mysql的机器。有条件的搞两台阿里云主机,没条件的装个vmare,装两台Linux系统的虚拟机,Ubuntu或者centos可随意。再或者一台机器跑两个MySQL的实例,跑在两个不同的端口3306和3307上。
使用ifconfig指令查看主机的ip地址。
| 主机1(主库) | 主机2(从库) |
|---|---|
| 192.168.91.134 | 192.168.91.137 |
3.2 主库配置
首先,修改主的配置:
find / -name 'my.cnf' #假定查找到的地址为/etc/mysql/my.cnf sudo vim /etc/mysql/my.cnf
在[mysqld]下添加如下的配置信息:
server-id=1 log-bin=master-bin log-bin-index=master-bin.index
修改完成后保存退出,接着使用如下的指令重启mysql:
service mysql restart
通过如下指令观察mysql是否重启成功:
ps -ef|grep mysqld mysql 5887 1 0 18:52 ? 00:00:00 /usr/sbin/mysqld root 6091 4169 0 18:52 pts/13 00:00:00 grep --color=auto mysqld
看到如上的显示说明重启成功,成功重启之后登陆mysql
mysql -u root -p 123
查看下主mysql的当前状态:
show master status;
显示信息如下:
+-------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +-------------------+----------+--------------+------------------+ | master-bin.000001 | 107 | | | +-------------------+----------+--------------+------------------+ 1 row in set (0.00 sec)
接下来创建一个用来复制主信息的账户,并赋予其备份的权限:
create user repl; grant replication slave on *.* to 'repl'@'192.168.91.137' identified by 'mysql'; flush privileges;
接下来创建一个测试的数据库,用于查看同步的结果:
create database o2o;
3.3 从库配置
下面开始配置从库
首先从修改从库的配置文件开始:
sudo vim /etc/mysql/my.cnf
在mysqld下添加如下的配置信息:
server-id=2 relay-log=slave-relay-bin relay-log-index=slave-relay-bin.index
保存退出后重启mysql,重启的方法除了上面的方法之外,这里再介绍另外一种方法:
/etc/init.d/mysql restart
同样通过上述的ps指令查看mysql的启动状态:
ps -ef|grep mysqld
下面登录mysql:
mysql -u root -p 123
下面为从库配置主库连接的相关信息:
change master to master_host='192.168.91.134',master_port=3306,master_user='repl',master_password='mysql',master_log_file='master-bin.000001',master_log_pos=0;
备注:这里的master_log_pos设置为0而不是107的原因在于,当前主库日志文件已经到位置107了,而从库尚未开始复制,自然是从0位置作为起始的复制点,而不是主库的当前位置107,否则主库通过指令create database o2o;新建库o2o的操作就无法同步过来了,后面基于这个库的指令重放可能会出问题。
执行
change master to master_host='ip', master_port=3306, master_user='xxx',master_password='xxx', master_log_file='mysql-bin.000012',master_log_pos=107;
抛出错误
ERROR 1201 (HY000): Could not initialize master info structure; more error messages can be found in the MySQL error log
解决办法:
stop slave; reset slave;
完成之后查看一下当前salave的状态:
show slave status \G;
显示信息如下:
*************************** 1. row *************************** Slave_IO_State: Master_Host: 192.168.91.134 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: master-bin.000001 Read_Master_Log_Pos: 4 Relay_Log_File: slave-relay-bin.000001 Relay_Log_Pos: 4 Relay_Master_Log_File: master-bin.000001 Slave_IO_Running: No Slave_SQL_Running: No Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 4 Relay_Log_Space: 107 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 0 1 row in set (0.00 sec)
这里重点关注到IO线程和SQL线程都没有启动:
Slave_IO_Running: No Slave_SQL_Running: No
考虑重启下mysql服务:
service mysql restart
进入再次进入从库查看从库的运行状态:
show alave status; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.91.134 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: master-bin.000001 Read_Master_Log_Pos: 492 Relay_Log_File: slave-relay-bin.000003 Relay_Log_Pos: 639 Relay_Master_Log_File: master-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 492 Relay_Log_Space: 795 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 1 row in set (0.00 sec)
此时发现,上面提到的两个线程都处于工作状态了。
接下来查看下从库的数据库:
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | o2o | | performance_schema | | scm | | shopping_mall | +--------------------+
可以看到,从库这边已经成功将主库的数据库信息同步过来了。
http://www.savh.cn/thread-1352.htm
转载请注明:Savh.Cn 发表


